


A decision tree is a technique used by the management of an organization to examine various decision points related to successive chance events that can assist in defining goals, preferences, benefits, risks, and objectives and can be applied to multiple critical investment areas. It is generally used in operations research and operations management. Another use of the decision tree is to calculate conditional probabilities. A decision tree is an explanatory tool.
The decision tree is used to determine the strategy with the highest probability of achieving the goal. It is an algorithm created using arrows and tiles. Additionally, it is a common tool used in machine learning.
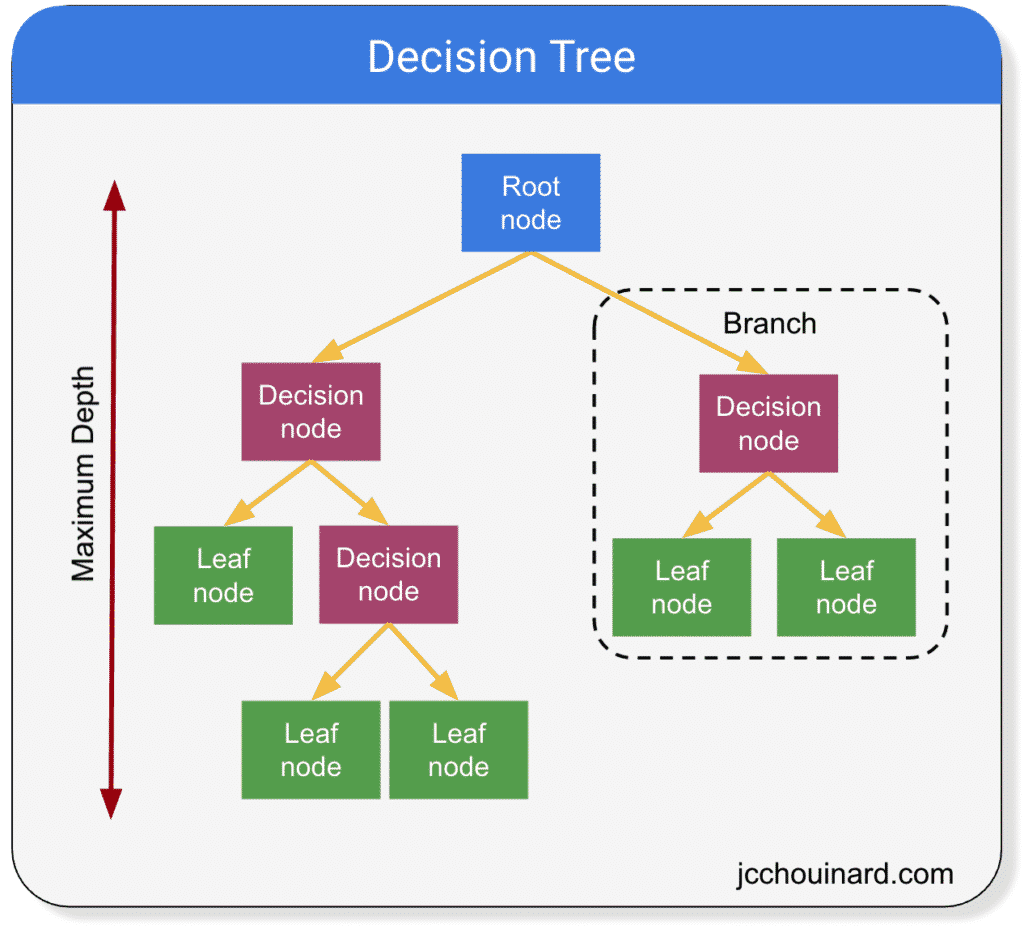
Building a decision tree starts from the root and goes step by step from the root to each leaf. These paths contain nodes and these nodes are represented in 3 ways:
1.Decision nodes - usually represented by squares.
2.Nodes of luck - typically represented by circles.
3.End nodes - typically represented by triangles.
Certain paths are followed during decision tree management. These ways are,
1.Identification of the problem
2..Constructing the decision tree
3.Determining the probabilities of occurrence of events
4.Calculation of the expected return for the respective chance point
5.Assignment of the highest expected return to the relevant decision point
6.Submission of the proposal
To find the most distinguishing feature in decision trees, information gain should be measured. To measure this gain, decision tree methods such as ID3, and C4.5 are used. In addition, entropy is used in the measurement of information gain. Entropy briefly indicates randomness, uncertainty, and the probability of the unexpected happening.





